
Hi!^1000 I'm Christian
Hi!^500 I'm a Research Scientist at Beyond Presence
Hi!^500 I'm working on conversational human avatars
Hi!^1000 I'm Christian
Hi!^500 I'm a Research Scientist at Beyond Presence
Hi!^500 I'm working on conversational human avatars
I'm Christian, a Research Scientist at Beyond Presence, working on the next generation of conversational real-time human avatars. I received my Ph.D. from TU Munich at the 3D AI Lab with Prof. Angela Dai. I completed my M.Sc. (Informatics) at TU Munich, working with Prof. Matthias Nießner, and my B.Sc. (Informatics) at the University of Augsburg, working with Christoph Lassner and Prof. Rainer Lienhart.
At Meta Reality Labs, I worked with Federica Bogo, Buğra Tekin, and Bharat Bhatnagar on generating 3D human motion using LLMs. I also worked with Minh Vo, Aayush Bansal, and Julian Straub on reconstruction and object detection approaches using neural rendering techniques.
My work focuses on recreating realistic environments, humans, and their interactions in a virtual space using a combination of generative modeling, neural rendering, and 3D reconstruction techniques. You can find my work on modeling 3D human behavior here and here, how to model human-object interactions here, how to capture 3D with KinectFusion, and completion of these captures.
news
Joined Beyond Presence to build the next generation of conversational real-time human avatars 🚀
I defended my Ph.D. thesis. Many thanks to Prof. Angela Dai and Prof. Michael Black 🎓
Working with Federica Bogo at Meta Reality Labs Research in Zürich on 3D human motion generation this summer 🏃♂️
Two papers accepted to CVPR 2024: CG-HOI and FutureHuman3D. See you in Seattle 🙂
Joining Meta Reality Labs Research in Seattle for the summer to work on 3D neural rendering approaches with Minh Vo 🎞️
Forecasting Characteristic 3D Poses of Human Actions accepted to CVPR 2022 in New Orleans ✈️
publications
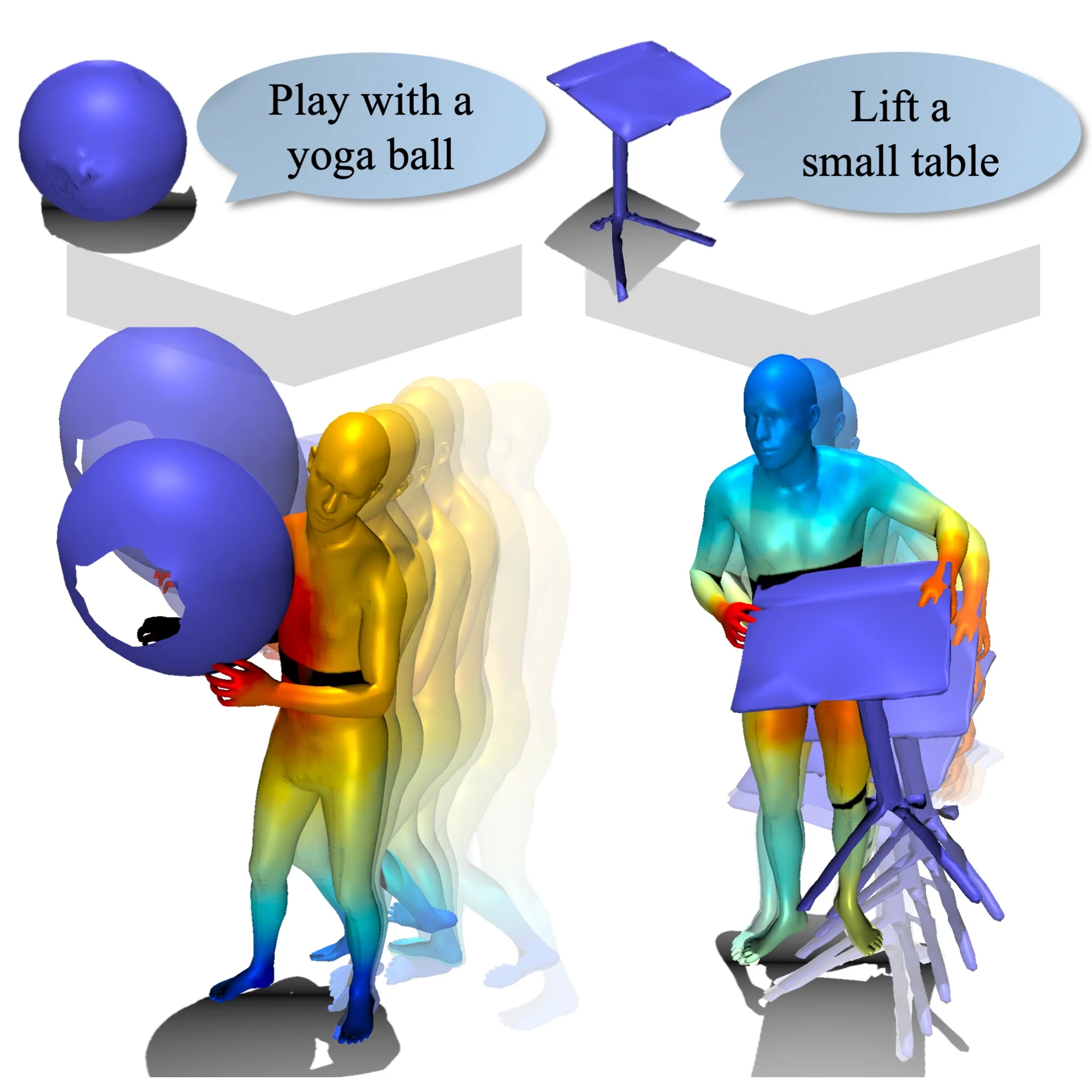
CG-HOI: Contact-Guided 3D Human-Object Interaction Generation
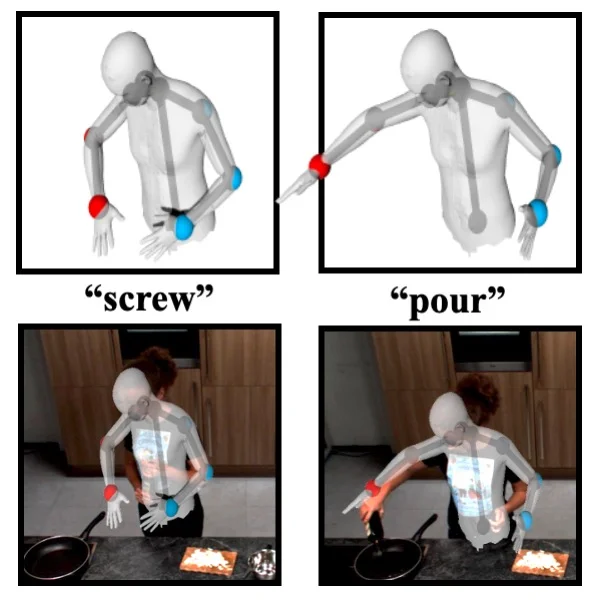
FutureHuman3D: Forecasting Complex Long-Term 3D Human Behavior from Video Observations
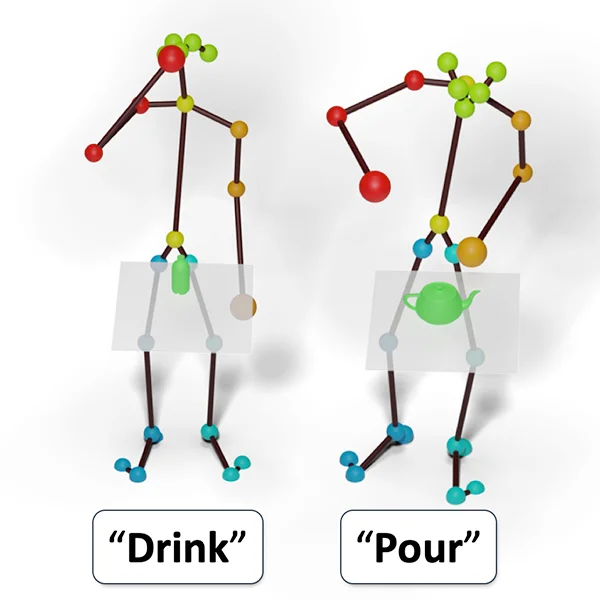
Forecasting Characteristic 3D Poses of Human Actions

SG-NN: Sparse Generative Neural Networks for Self-Supervised Scene Completion of RGB-D Scans
theses

3D Human Behavior Generation through Action and Interaction Synthesis
Learning how to share a common space between autonomous systems and humans requires the capability to understand, generate, and forecast human actions and interactions.
30 Dec 2024

3D Shape Completion from Sparse Point Clouds Using Deep Learning
We tackle the problem of generating dense representations from sparse and partial point clouds. We achieve this with a data-driven approach which learns to complete incoming sets of 3D points in a fully-supervised manner.
15 Jul 2019
projects
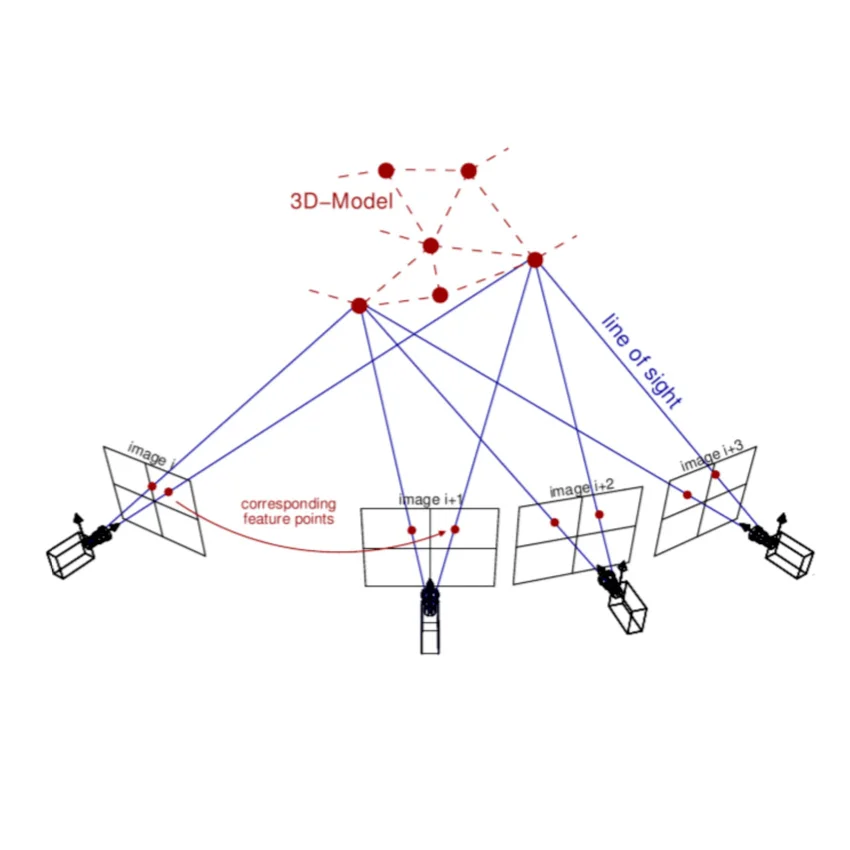
BundleACeres - Structure from Motion using Bundle Adjustment with the Ceres Solver
An implementation of Bundle Adjustment with the Ceres Solver as optimizer. It matches a chain of incoming RGB images using ORB keypoints and BRISK descriptors in order to find 3D points. The Ceres Solver is then used to jointly solve for the locations of 3D points and camera poses of the frames. It is implemented in modern C++14 and utilizes OpenCV 3, Ceres, PCL and others.

KinectFusionLib - Modern Implementation of the KinectFusion Approach
Implementation of the KinectFusion approach to generating three-dimensional models from depth image scans. Here, the original method has been extended with the MarchingCubes algorithm to allow exporting the model as a dense surface mesh. Realized in modern C++14 and CUDA to allow real-time reconstruction. Developed in the context of an interdisciplinary project in cooperation with the Chair for Computer Aided Medical Procedures and Augmented Reality and Dynamify GmbH.

VideoMagnification - Magnify motions and detect heartbeats
This application allows the user to magnify motion and detect heartbeats from videos and webcam video streams. It is an implementation of Wu, Hao-Yu, et al.: "Eulerian video magnification for revealing subtle changes in the world". You can find out more about motion magnification on the project homepage. My implementation can be found here. It makes use of modern C++11, the open-source vision library OpenCV 3.1 and the UI framework QT 5.
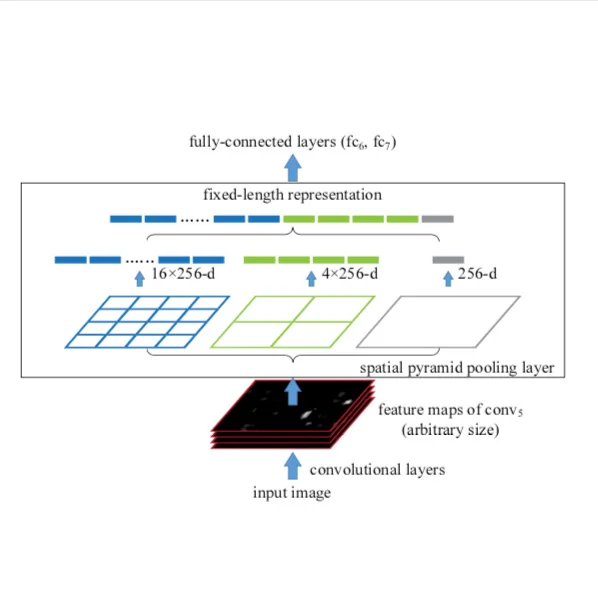
Spatial Pyramid Pooling as an additional layer in caffe
An implementation of the concept proposed in He, Kaiming, et al. "Spatial pyramid pooling in deep convolutional networks for visual recognition". It adds a new custom layer to the AlexNet architecture which performs spatial pyramid pooling in order to remove the network's need for fixed-size input images. This was part of my Bachelor's Thesis which I wrote at the Multimedia Computing and Computer Vision Lab, University of Augsburg under the supervision of...
Training methods for the decision forest library fertilized forests
Worked with Christoph Lassner on his library fertilized forests and implemented several boosted training methods like AdaBoost and SAMME. You can have a look at the project homepage or read the paper which received an honorable mention at the ACM MM OSSC 2015.
photography
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Check out my 500px page for more pictures.